:硬架构
1:机房的选择:
在选择机房的时候,根据网站用户的地域分布,可以选择网通或电信机房,但更多时候,可能双线机房才是合适的。越大的城市,机房价格越贵,从成本的角度看可以在一些中小城市托管服务器,比如说广州的公司可以考虑把服务器托管在东莞,佛山等地,不是特别远,但是价格会便宜很多。
2:带宽的大小:
通常老板花钱请我们架构网站的时候,会给我们提出一些目标,诸如网站每天要能承受100万PV的访问量等等。这时我们要预算一下大概需要多大的带宽,计算带宽大小主要涉及两个指标(峰值流量和页面大小),我们不妨在计算前先做出必要的假设:
第一:假设峰值流量是平均流量的5倍。
第二:假设每次访问平均的页面大小是100K字节左右。
如果100万PV的访问量在一天内平均分布的话,折合到每秒大约12次访问,如果按平均每次访问页面的大小是100K字节左右计算的话,这12次访 问总计大约就是1200K字节,字节的单位是Byte,而带宽的单位是bit,它们之间的关系是1Byte = 8bit,所以1200K Byte大致就相当于9600K bit,也就是9Mbps的样子,实际情况中,我们的网站必须能在峰值流量时保持正常访问,所以按照假设的峰值流量算,真实带宽的需求应该在45Mbps 左右。
当然,这个结论是建立在前面提到的两点假设的基础上,如果你的实际情况和这两点假设有出入,那么结果也会有差别。
3:服务器的划分:
先看我们都需要哪些服务器:图片服务器,页面服务器,数据库服务器,应用服务器,日志服务器等等。
对于访问量大点的网站而言,分离单独的图片服务器和页面服务器相当必要,我们可以用lighttpd来跑图片服务器,用apache来跑页面服务 器,当然也可以选择别的,甚至,我们可以扩展成很多台图片服务器和很多台页面服务器,并设置相关域名,如img.domain.com和 www.domain.com,页面里的图片路径都使用绝对路径,如<img src="http://img.domain.com/abc.gif" />,然后设置DNS轮循,达到最初级的负载均衡。当然,服务器多了就不可避免的涉及一个同步的问题,这个可以使用rsync软件来搞定。
数据库服务器是重中之重,因为网站的瓶颈问题十有八九是出在数据库身上。现在一般的中小网站多使用MySQL数据库,不过它的集群功能似乎还没有达 到stable的阶段,所以这里不做评价。一般而言,使用MySQL数据库的时候,我们应该搞一个主从(一主多从)结构,主数据库服务器使用innodb 表结构,从数据服务器使用myisam表结构,充分发挥它们各自的优势,而且这样的主从结构分离了读写操作,降低了读操作的压力,甚至我们还可以设定一个专门的从服务器做备份服务器,方便备份。不然如果你只有一台主服务器,在大数据量的情况下,mysqldump基本就没戏了,直接拷贝数据文件的话,还得先停止数据库服务再拷贝,否则备份文件会出错。但对于很多网站而言,即使数据库服务仅停止了一秒也是不可接受的。如果你有了一台从数据库服务器,在备份数 据的时候,可以先停止服务(slave stop)再备份,再启动服务(slave start)后从服务器会自动从主服务器同步数据,一切都没有影响。但是主从结构也是有致命缺点的,那就是主从结构只是降低了读操作的压力,却不能降低写操作的压力。为了适应更大的规模,可能只剩下最后这招了:横向/纵向分割数据库。所谓横向分割数据库,就是把不同的表保存到不同的数据库服务器上,比如说用户表保存在A数据库服务器上,文章表保存在B数据库服务器上,当然这样的分割是有代价的,最基本的就是你没法进行LEFT JOIN之类的操作了。所谓纵向分割数据库,一般是指按照用户标识(user_id)等来划分数据存储的服务器,比如说:我们有5台数据库服务器,那么 “user_id % 5 + 1”等于1的就保存到1号服务器,等于2的就保存到2好服务器,以此类推,纵向分隔的原则有很多种,可以视情况选择。不过和横向分割数据库一样,纵向分割 数据库也是有代价的,最基本的就是我们在进行如COUNT, SUM等汇总操作的时候会麻烦很多。综上所述,数据库服务器的解决方案一般视情况往往是一个混合的方案,以其发挥各种方案的优势,有时候还需要借助 memcached之类的第三方软件,以便适应更大访问量的要求。
如果有专门的应用服务器来跑PHP脚本是最合适不过的了,那样我们的页面服务器只保存静态页面就可以了,可以给应用服务器设置一些诸如 app.domain.com之类的域名来和页面服务器加以区别。对于应用服务器,我还是更倾向于使用prefork模式的apache,配上必要的 xcache之类的PHP缓存软件,加载模块要越少越好,除了mod_rewrite等必要的模块,不必要的东西统统舍弃,尽量减少httpd进程的内存消耗,而那些图片服务器,页面服务器等静态内容就可以使用lighttpd或者tux来搞,充分发挥各种服务器的特点。
如果条件允许,独立的日志服务器也是必要的,一般小网站的做法都是把页面服务器和日志服务器合二为一了,在凌晨访问量不大的时候cron运行前一天 的日志计算,不过如果你使用awstats之类的日志分析软件,对于百万级访问量而言,即使按天归档,也会消耗很多时间和服务器资源去计算,所以分离单独的日志服务器还是有好处的,这样不会影响正式服务器的工作状态。
二:软架构
1:框架的选择:
现在的PHP框架有很多选择,比如:CakePHP,Symfony,Zend Framework等等,至于应该使用哪一个并没有唯一的答案,要根据Team里团队成员对各个框架的了解程度而定。很多时候,即使没有使用框架,一样能写出好的程序来,比如Flickr据说就是用Pear+Smarty这样的类库写出来的,所以是否用框架,用什么框架,一般不是最重要,重要的是我们的编程思想里要有框架的意识。
现在的.NET框架有很多选择,比如:cnForums,.text,cs, Castle,等等
2:逻辑的分层:
网站规模到了一定的程度之后,代码里各种逻辑纠缠在一起,会给维护和扩展带来巨大的障碍,这时我们的解决方式其实很简单,那就是重构,将逻辑进行分层。通常,自上而下可以分为表现层,应用层,领域层,持久层。
所谓表现层,并不仅仅就指模板,它的范围要更广一些,所有和表现相关的逻辑都应该被纳入表现层的范畴。比如说某处的字体要显示为红色,某处的开头要空两格,这些都属于表现层。很多时候,我们容易犯的错误就是把本属于表现层的逻辑放到了其他层面去完成,这里说一个很常见的例子:我们在列表页显示文章标题的时候,都会设定一个最大字数,一旦标题长度超过了这个限制,就截断,并在后面显示“..”,这就是最典型的表现层逻辑,但是实际情况,有很多程序员都是在非表现层代码里完成数据的获取和截断,然后赋值给表现层模板,这样的代码最直接的缺点就是同样一段数据,在这个页面我可能想显示前10个字,再另一个 页面我可能想显示前15个字,而一旦我们在程序里固化了这个字数,也就丧失了可移植性。正确的做法是应该做一个视图助手之类的程序来专门处理此类逻辑,比如说:Smarty里的truncate就属于这样的视图助手(不过它那个实现不适合中文)。
所谓应用层,它的主要作用是定义用户可以做什么,并把操作结果反馈给表现层。至于如何做,通常不是它的职责范围(而是领域层的职责范围),它会通过委派把如何做的工作交给领域层去处理。在使用MVC架构的网站中,我们可以看到类似下面这样的URL: domain.com/articles/view/123,其内部编码实现,一般就是一个Articles控制器类,里面有一个view方法,这就是一 个典型的应用层操作,因为它定义了用户可以做一个查看的动作。在MVC架构中,有一个准则是这么说的:Rich Model Is Good。言外之意,就是Controller要保持“瘦”一些比较好,进而说明应用层要尽量简单,不要包括涉及领域内容的逻辑。
所谓领域层,最直接的解释就是包含领域逻辑的层。它是一个软件的灵魂所在。先来看看什么叫领域逻辑,简单的说,具有明确的领域概念的逻辑就是领域逻辑,比如我们在ATM机上取钱,过程大致是这样的:插入银联卡,输入密码,输入取款金额,确定,拿钱,然后ATM吐出一个交易凭条。在这个过程中,银联卡 在ATM机器里完成钱从帐户上划拨的过程就是一个领域逻辑,因为取钱在银行中是一个明确的领域概念,而ATM机吐出一个交易凭条则不是领域逻辑,而仅是一 个应用逻辑,因为吐出交易凭条并不是银行中一个明确的领域概念,只是一种技术手段,对应的,我们取钱后不吐交易凭条,而发送一条提醒短信也是可能的,但并不是一定如此,如果在实际情况中,我们要求取款后必须吐出交易凭条,也就是说吐出交易凭条已经和取款紧密结合,那么你也可以把吐出交易凭条看作是领域逻辑 的一部分,一切都以问题的具体情况而定。在Eric那本经典的领域驱动设计中,把领域层分为了五种基本元素:实体,值对象,服务,工厂,仓储。具体可以参 阅书中的介绍。领域层最常犯的错误就是把本应属于领域层的逻辑泄露到了其他层次,比如说在一个CMS系统,对热门文章的定义是这样的:每天被浏览的次数多 于1000次,被评论的次数多于100次,这样的文章就是热门文章。对于一个CMS来说,热门文章这个词无疑是一个重要的领域概念,那么我们如何实现这个逻辑的设计的?你可能会给出类似下面的代码:“SELECT ... FROM ... WHERE 浏览 > 1000 AND 评论 > 100”,没错,这是最简单的实现方式,但是这里需要注意的是“每天被浏览的次数多于1000次,被评论的次数多于100次”这个重要的领域逻辑被隐藏到了SQL语句中,SQL语句显然不属于领域层的范畴,也就是说,我们的领域逻辑泄露了。
所谓持久层,就是指把我们的领域模型保存到数据库中。因为我们的程序代码是面向对象风格的,而数据库一般是关系型的数据库,所以我们需要把领域模型 碾平,才能保存到数据库中,但是在PHP里,直到目前还没有非常好的ORM出现,所以这方面的解决方案不是特别多,参考Martin的企业应用架构模式一 书,大致可以使用的方法有行数据入口(Row Data Gateway)或者表数据入口(Table Data Gateway),或者把领域层和持久层合二为一变成活动记录(Active Record)的方式。
我们知道,对于一个大型网站来说,可伸缩性是非常重要的,怎么样在纵向和横向有良好的可伸缩性,就需要在做架构设计的时候考虑到一个分的原则,我想在多个方面说一下怎么分:
首先是横向的分:
1. 大的网站化解为多个小网站:当我们一个网站有多个功能的时候,可以考虑把这个网站拆分成几个小模块,每一个模块可以是一个网站,这样的话我们到时候就可以很灵活地去把这些网站部署到不同的服务器上。
2. 静态动态分离:静态文件和动态文件最好分离开成2个网站,我们知道静态网站和动态网站对服务器来说压力的侧重不同,前者可能重IO后者重CPU,那么我们在选择硬件的时候也可以有侧重,而且静态和动态内容的缓存策略也不一样。典型的应用,我们一般会有独立的文件或图片服务器。
3. 按照功能来分:比如有一个模块是负责上传的,上传操作很消耗时间,如果和其它应用混在一起的话很可能,一点点访问就会使服务器瘫痪,这种特殊的模块应该分开。安全的不安全的也要分开,还需要考虑到以后SSL的购买。
4. 我们不一定要全部用自己的服务器,搜索、报表可以依靠别人的服务,比如google的搜索和报表服务,自己做的不一定比得过别人,服务器带宽都省了。
其次是纵向的分:
1. 文件也相当于数据库,IO的流量可能比数据库还大,这也算是纵向级别的访问,上传的文件图片一定要和WEB服务器分开。当然,数据库和网站都放在一个服务器上的很少了,这是最基本的。
2. 对于涉及到数据库访问的动态程序来说,我们可以使用一个中间层(所谓的应用层或逻辑层)来访问数据库(部署在独立的服务器上),最大的好处就是缓存和灵活性。缓存的内存占用比较大,我们要把它和网站进程分开,而且这样做我们可以很方便的去改变一些数据访问的策略,即使到时候数据库有分布的话在这里可以做一个调配工作,这样灵活性就很大了。还有好处是中间层可以做电线网通桥梁,可能网通访问双线再访问电信会比网通直接访问电信服务器快。
有人说我不分,我可以做负载均衡,对,是可以的,但是如果分的话,同样的10台机器肯定比不分10台机器可以承受更多的访问量,而且对硬件的需求可能不会很高,因为知道需要哪个硬件特别好。争取让每一个服务期都不空闲,又都不是太忙,合理进行组合调整和扩充,这样的系统伸缩性就高了,能根据访问量来调整的前提就是之前有考虑到分,分的好处是灵活性、伸缩性、隔离性以及安全性。
对服务器来说,我们有几点是要长期观察的,任何一点都可能是瓶颈:
1. CPU:动态文件的解析需要比较多的CPU,CPU出现瓶颈就要看是不是哪个功能过长时间占用线程,如果是就分出去。或者就是每一个请求处理时间不长,但是访问量很高,那么就加服务器。CPU是好东西,不能让他干等,不做事情。
2. 内存:缓存从IIS进程独立出去,一般对WEB服务器来说内存不够的情况不是很多。内存比磁盘快,要合理利用。
3. 磁盘IO:用性能监视器找到哪些文件IO特别大,找到了就分到独立的一组文件服务器上去,或者直接做CDN。磁盘慢,大规模读取数据的应用靠缓存,大规模写入数据的应用可以靠队列来降低突发的并发。
4. 网络:我们知道,网络的通讯是比较慢的,比磁盘还慢,如果是做分布式缓存,分布式计算的话,要考虑到物理服务器之间网络通讯的时间,当然,在流量大了以后,这可以提高系统的接纳能力一个等级。静态内容可以借助CSD分担一部分,在做服务器假设的时候还要考虑中国特色的电信网通情况以及防火墙。
对SQL SERVER数据库服务器来说[UPDATE]:
其实还是水平分割和纵向分割,一个二维表,水平分割就是横过来切一刀,纵向分割就是竖直切一刀:
1、纵向分割就是,我们不同的应用可以分到不同的DB中,不同的实例中,或者说把某个拥有很多字段的表拆分成小表。
2、横向分割就是,某些应用可能不负载,比如用户注册,但是用户表会非常大,可以把大表分开。可以采用表分区,数据存储在不同文件上,然后再部署到独立物理服务器增加IO吞吐以改善读写性能,土一点的做法就是自己定期把老的数据存档。表分区的另外一个优势可以增加数据查询速度,因为我们的页索引可以有多层了,就像一个文件夹中的文件不要太多,多分几层文件夹一样。
3、还可以通过数据库镜像、复制订阅、事物日志,把读写分开到不同的镜像物理数据库上,一般来说够用,如果还不行可以用硬件来实现数据库的负载均衡。当然,对于BI,我们可能还会有数据仓库。
架构上考虑到了这些之后,流量大了,就可以在这个的基础上再去调整或者做WEB服务器或者应用服务器的负载均衡。很多时候我们都是在重复发现问题-》找到瓶颈-》解决这个过程。
典型的架构如下: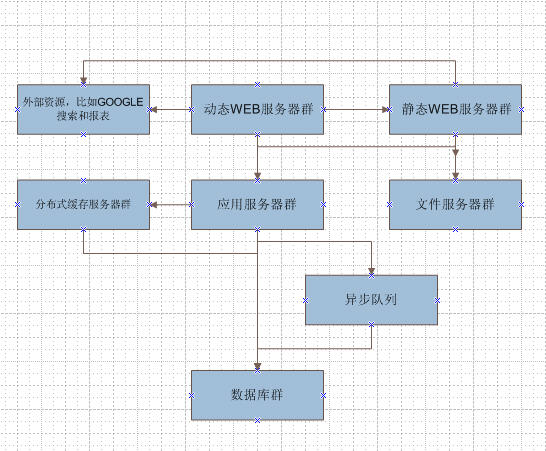
动态WEB服务器配好点的CPU,静态WEB服务器和文件服务器磁盘好点
应用服务器内存大点,缓存服务器也是,数据库服务器当然内存和CPU都要好